




Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
A brief Apache Kafka background
Apache Kafka is written in Scala and Java and is the creation of former LinkedIn data engineers. As early as 2011, the technology was handed over to the open-source community as a highly scalable messaging system. Today, Apache Kafka is part of the Confluent Stream Platform and handles trillions of events every day. Apache Kafka has established itself on the market with many trusted companies waving the Kafka banner.

Source: https://kafka.apache.org/
This article is a beginners guide to Apache Kafka basic architecture, components, concepts etc. Here we will try and understand what is Kafka, what are the use cases of Kafka, what are some basic APIs and components of Kafka ecosystem.
What is event streaming?
Event streaming is the digital equivalent of the human body’s central nervous system. It is the technological foundation for the ‘always-on’ world where businesses are increasingly software-defined and automated, and where the user of software is more software.
Technically speaking, event streaming is the practice of capturing data in real-time from event sources like databases, sensors, mobile devices, cloud services, and software applications in the form of streams of events; storing these event streams durably for later retrieval; manipulating, processing, and reacting to the event streams in real-time as well as retrospectively; and routing the event streams to different destination technologies as needed. Event streaming thus ensures a continuous flow and interpretation of data so that the right information is at the right place, at the right time.
What can I use event streaming for?
Event streaming is applied to a wide variety of use cases across a plethora of industries and organizations. Its many examples include:
- To process payments and financial transactions in real-time, such as in stock exchanges, banks, and insurances.
- To track and monitor cars, trucks, fleets, and shipments in real-time, such as in logistics and the automotive industry.
- To continuously capture and analyze sensor data from IoT devices or other equipment, such as in factories and wind parks.
- To collect and immediately react to customer interactions and orders, such as in retail, the hotel and travel industry, and mobile applications.
- To monitor patients in hospital care and predict changes in condition to ensure timely treatment in emergencies.
- To connect, store, and make available data produced by different divisions of a company.
- To serve as the foundation for data platforms, event-driven architectures, and microservices.
Apache Kafka is an event streaming platform. What does that mean?
Kafka combines three key capabilities so you can implement your use cases for event streaming end-to-end with a single battle-tested solution:
- To publish (write) and subscribe to (read) streams of events, including continuous import/export of your data from other systems.
- To store streams of events durably and reliably for as long as you want.
- To process streams of events as they occur or retrospectively.
And all this functionality is provided in a distributed, highly scalable, elastic, fault-tolerant, and secure manner. Kafka can be deployed on bare-metal hardware, virtual machines, and containers, and on-premises as well as in the cloud. You can choose between self-managing your Kafka environments and using fully managed services offered by a variety of vendors.
Main Concepts and Terminology
An event records the fact that “something happened” in the world or in your business. It is also called record or message in the documentation. When you read or write data to Kafka, you do this in the form of events. Conceptually, an event has a key, value, timestamp, and optional metadata headers. Here’s an example event:
- Event key: “Alice”
- Event value: “Made a payment of $200 to Bob”
- Event timestamp: “Jun. 25, 2020 at 2:06 p.m.”
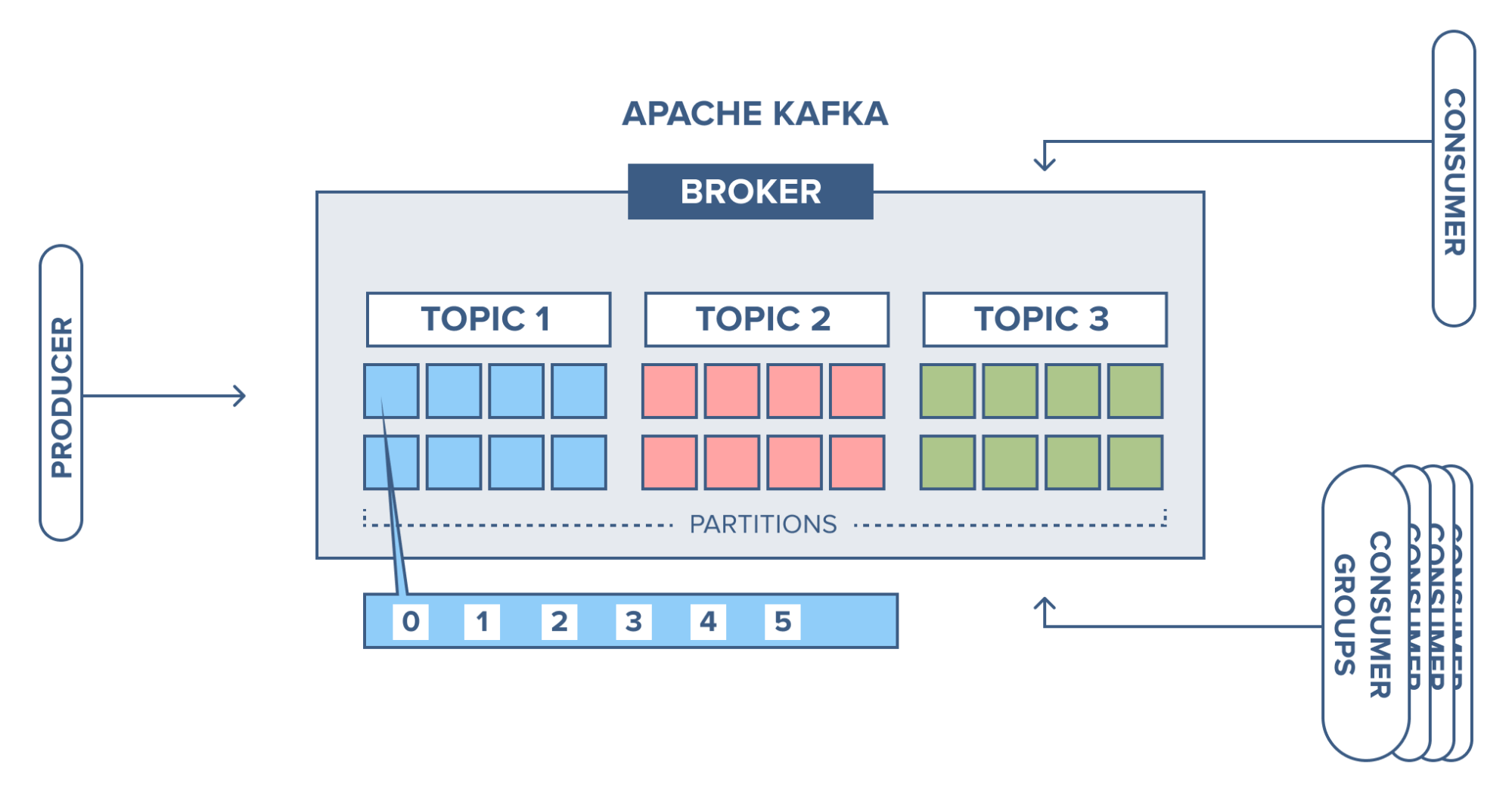
Producers are those client applications that publish (write) events to Kafka, and consumers are those that subscribe to (read and process) these events. In Kafka, producers and consumers are fully decoupled and agnostic of each other, which is a key design element to achieve the high scalability that Kafka is known for. For example, producers never need to wait for consumers. Kafka provides various guarantees such as the ability to process events exactly-once.
Events are organized and durably stored in topics. Very simplified, a topic is similar to a folder in a filesystem, and the events are the files in that folder. An example topic name could be “payments”. Topics in Kafka are always multi-producer and multi-subscriber: a topic can have zero, one, or many producers that write events to it, as well as zero, one, or many consumers that subscribe to these events. Events in a topic can be read as often as needed — unlike traditional messaging systems, events are not deleted after consumption. Instead, you define for how long Kafka should retain your events through a per-topic configuration setting, after which old events will be discarded. Kafka’s performance is effectively constant with respect to data size, so storing data for a long time is perfectly fine.
Topics are partitioned, meaning a topic is spread over a number of “buckets” located on different Kafka brokers. This distributed placement of your data is very important for scalability because it allows client applications to both read and write the data from/to many brokers at the same time. When a new event is published to a topic, it is actually appended to one of the topic’s partitions. Events with the same event key (e.g., a customer or vehicle ID) are written to the same partition, and Kafka guarantees that any consumer of a given topic-partition will always read that partition’s events in exactly the same order as they were written.

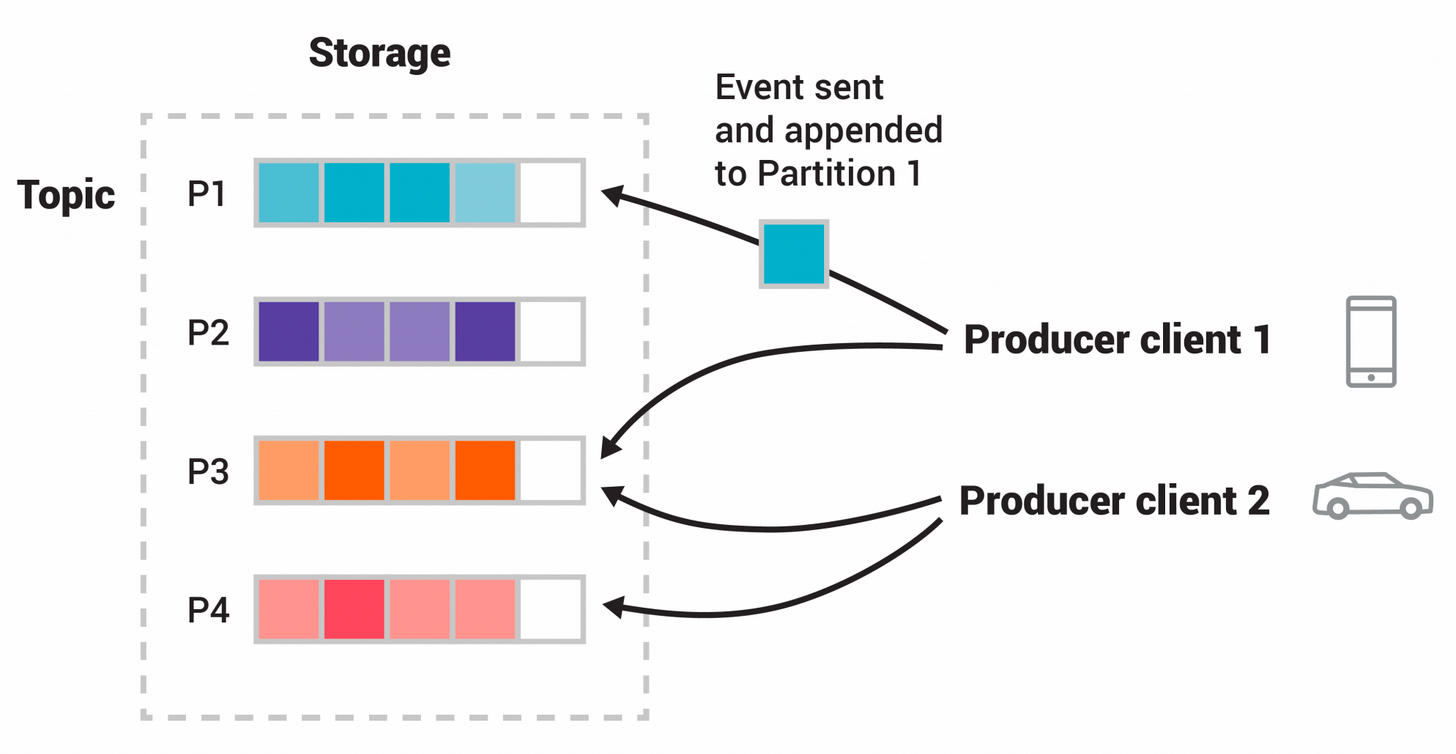
(source: https://kafka.apache.org/)
This example topic has four partitions P1–P4. Two different producer clients are publishing, independently from each other, new events to the topic by writing events over the network to the topic’s partitions. Events with the same key (denoted by their color in the figure) are written to the same partition.
To make your data fault-tolerant and highly-available, every topic can be replicated, even across geo-regions or datacenters, so that there are always multiple brokers that have a copy of the data just in case things go wrong, you want to do maintenance on the brokers, and so on. A common production setting is a replication factor of 3, i.e., there will always be three copies of your data. This replication is performed at the level of topic-partitions.
This primer should be sufficient for an introduction. The Design section of the documentation explains Kafka’s various concepts in full detail, if you are interested.
Use Cases
Kafka has many use cases. I have listed some of the very popular ones below.
Messaging
Kafka works well as a replacement for a more traditional message broker. Message brokers are used for a variety of reasons (to decouple processing from data producers, to buffer unprocessed messages, etc). In comparison to most messaging systems Kafka has better throughput, built-in partitioning, replication, and fault-tolerance which makes it a good solution for large scale message processing applications.
In our experience messaging uses are often comparatively low-throughput, but may require low end-to-end latency and often depend on the strong durability guarantees Kafka provides.
In this domain Kafka is comparable to traditional messaging systems such as ActiveMQ or RabbitMQ.
Website Activity Tracking
The original use case for Kafka was to be able to rebuild a user activity tracking pipeline as a set of real-time publish-subscribe feeds. This means site activity (page views, searches, or other actions users may take) is published to central topics with one topic per activity type. These feeds are available for subscription for a range of use cases including real-time processing, real-time monitoring, and loading into Hadoop or offline data warehousing systems for offline processing and reporting.
Activity tracking is often very high volume as many activity messages are generated for each user page view.
Source: https://www.cloudkarafka.com/
Metrics
Kafka is often used for operational monitoring data. This involves aggregating statistics from distributed applications to produce centralized feeds of operational data.
Log Aggregation
Many people use Kafka as a replacement for a log aggregation solution. Log aggregation typically collects physical log files off servers and puts them in a central place (a file server or HDFS perhaps) for processing. Kafka abstracts away the details of files and gives a cleaner abstraction of log or event data as a stream of messages. This allows for lower-latency processing and easier support for multiple data sources and distributed data consumption. In comparison to log-centric systems like Scribe or Flume, Kafka offers equally good performance, stronger durability guarantees due to replication, and much lower end-to-end latency.
Web Shop
Think of a webshop with a ‘similar products’ feature on the site. To make this work, each action performed by a consumer is recorded and sent to Kafka. A separate application comes along and consumes these messages, filtering out the products the consumer has shown an interest in and gathering information on similar products. This ‘similar product’ information is then sent back to the webshop for it to display to the consumer in real-time.
Alternatively, since all data is persistent in Kafka, a batch job can run overnight on the ‘similar product’ information gathered by the system, generating an email for the customer with suggestions of products.
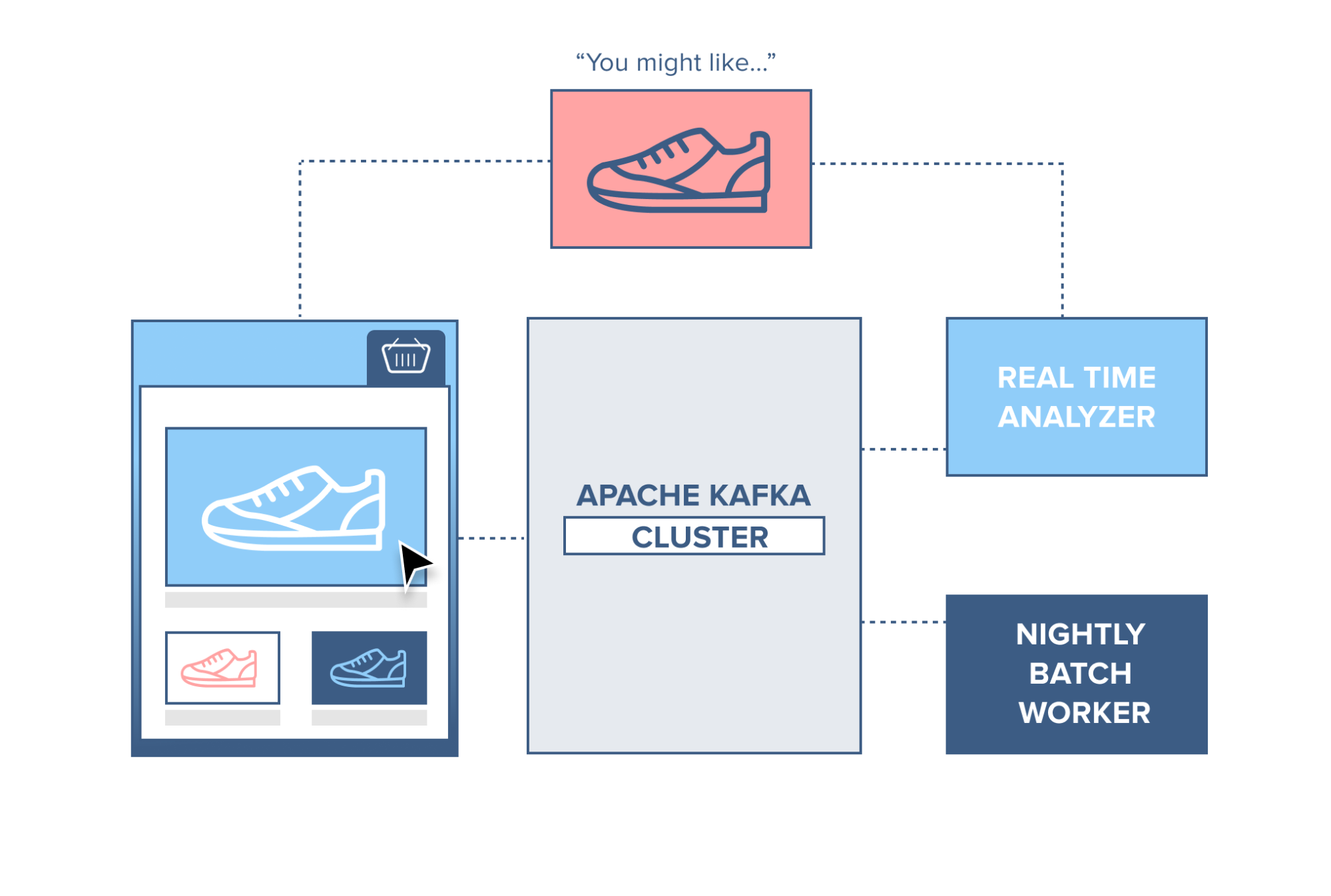
Source: https://www.cloudkarafka.com/
Stream Processing
Many users of Kafka process data in processing pipelines consisting of multiple stages, where raw input data is consumed from Kafka topics and then aggregated, enriched, or otherwise transformed into new topics for further consumption or follow-up processing. For example, a processing pipeline for recommending news articles might crawl article content from RSS feeds and publish it to an “articles” topic; further processing might normalize or deduplicate this content and publish the cleansed article content to a new topic; a final processing stage might attempt to recommend this content to users. Such processing pipelines create graphs of real-time data flows based on the individual topics. Starting in 0.10.0.0, a light-weight but powerful stream processing library called Kafka Streams is available in Apache Kafka to perform such data processing as described above. Apart from Kafka Streams, alternative open source stream processing tools include Apache Storm and Apache Samza.
Kafka as a Database
Apache Kafka has another interesting feature not found in RabbitMQ — log compaction. Log compaction ensures that Kafka always retains the last known value for each record key. Kafka simply keeps the latest version of a record and deletes the older versions with the same key.
An example of log compaction use is when displaying the latest status of a cluster among thousands of clusters running. The current status of the cluster is written into Kafka and the topic is configured to compact the records. When this topic is consumed, it displays the latest status first and then a continuous stream of new statuses.
Source: https://www.cloudkarafka.com/
Event Sourcing
Event sourcing is a style of application design where state changes are logged as a time-ordered sequence of records. Kafka’s support for very large stored log data makes it an excellent backend for an application built in this style.
Application health monitoring
Servers can be monitored and set to trigger alarms in case of rapid changes in usage or system faults. Information from server agents can be combined with the server syslog and sent to a Kafka cluster. Through Kafka Streams, these topics can be joined and set to trigger alarms based on usage thresholds, containing full information for easier troubleshooting of system problems before they become catastrophic.
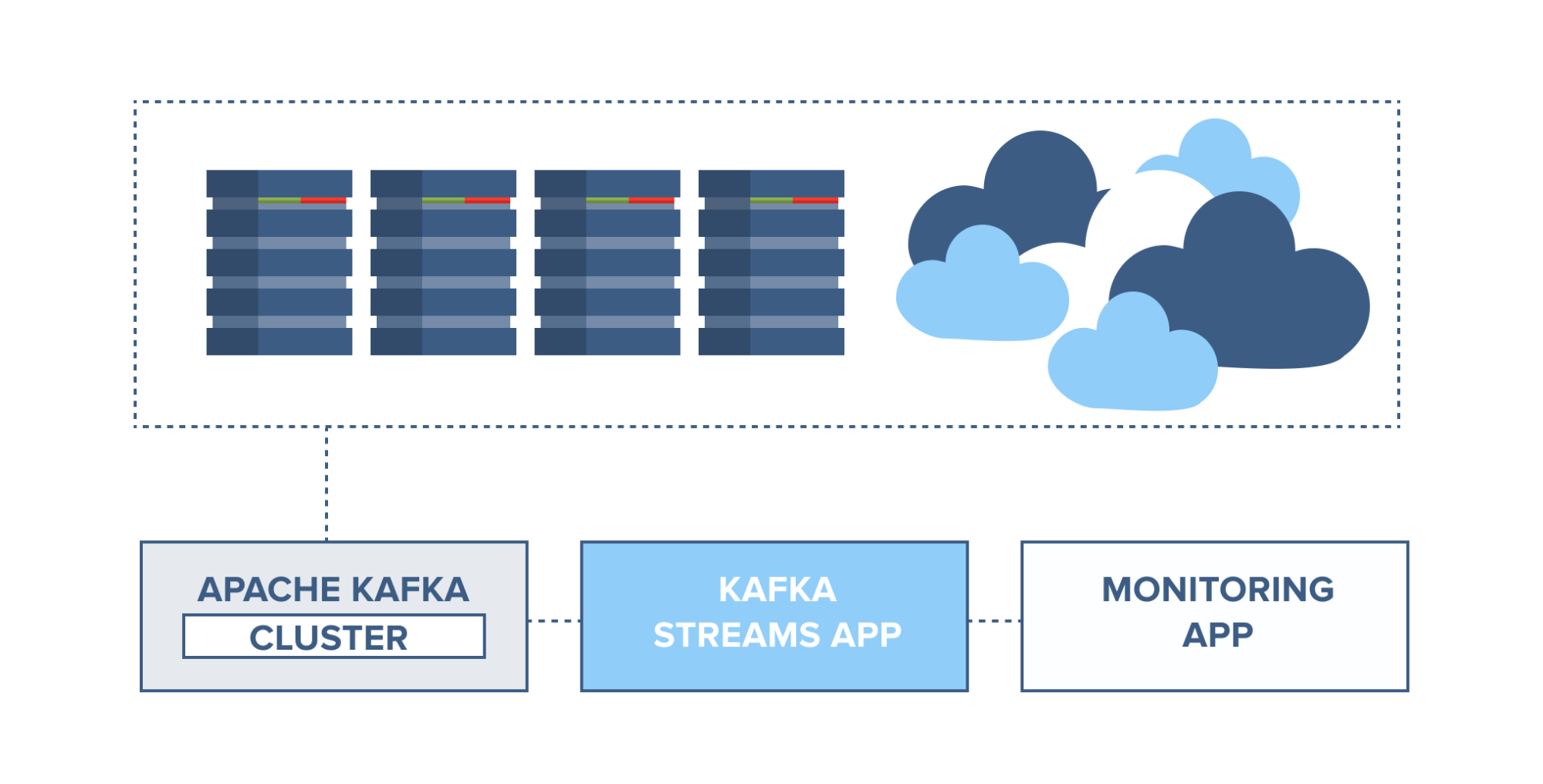
Source: https://www.cloudkarafka.com/
Commit Log
Kafka can serve as a kind of external commit-log for a distributed system. The log helps replicate data between nodes and acts as a re-syncing mechanism for failed nodes to restore their data. The log compaction feature in Kafka helps support this usage. In this usage Kafka is similar to Apache BookKeeper project.
Kafka Fundamental Concepts
In this section we’ll go over some fundamental concepts of Kafka. It’s imperative to have a clear understanding of these concepts. The concepts will be useful when we start working tutorials.
Topics
A Topic is a category/feed name to which records are stored and published.
The topic is a logical channel to which producers publish message and from which the consumers receive messages.
- A topic defines the stream of a particular type/classification of data, in Kafka.
- Moreover, here messages are structured or organized. A particular type of messages is published on a particular topic.
- Basically, at first, a producer writes its messages to the topics. Then consumers read those messages from topics.
- In a Kafka cluster, a topic is identified by its name and must be unique.
- There can be any number of topics, there is no limitation.
- We can not change or update data, as soon as it gets published.
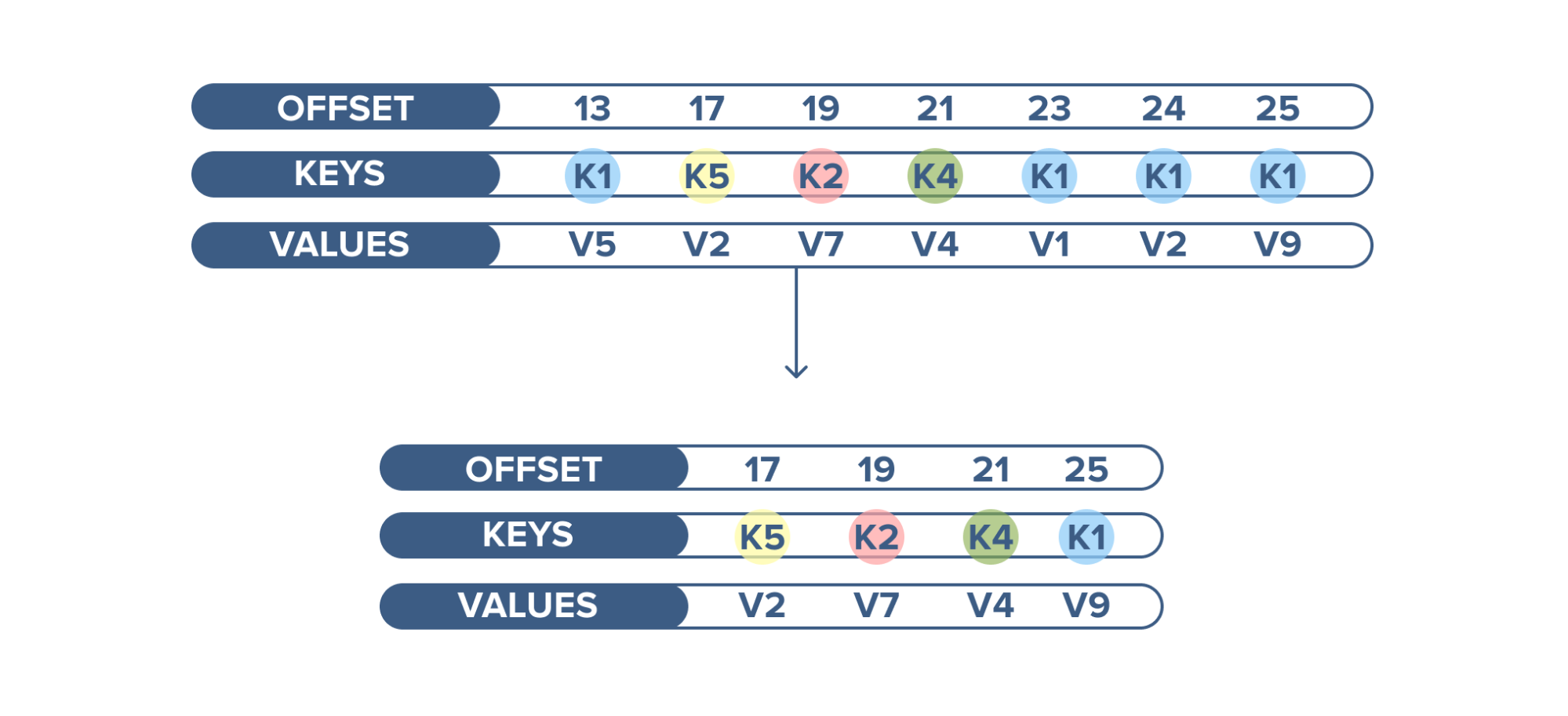
Kafka retains records in the log, making the consumers responsible for tracking the position in the log, known as the “offset”. Typically, a consumer advances the offset in a linear manner as messages are read. However, the position is actually controlled by the consumer, which can consume messages in any order. For example, a consumer can reset to an older offset when reprocessing records.
Partitions
In a Kafka cluster, Topics are split into Partitions and also replicated across brokers.
- However, to which partition a published message will be written, there is no guarantee about that.
- Also, we can add a key to a message. Basically, we will get ensured that all these messages (with the same key) will end up in the same partition if a producer publishes a message with a key. Due to this feature, Kafka offers message sequencing guarantee. Though, unless a key is added to it, data is written to partitions randomly.
- Moreover, in one partition, messages are stored in the sequenced fashion.
- In a partition, each message is assigned an incremental id, also called offset.
- However, only within the partition, these offsets are meaningful. Moreover, in a topic, it does not have any value across partitions.
- There can be any number of Partitions, there is no limitation.
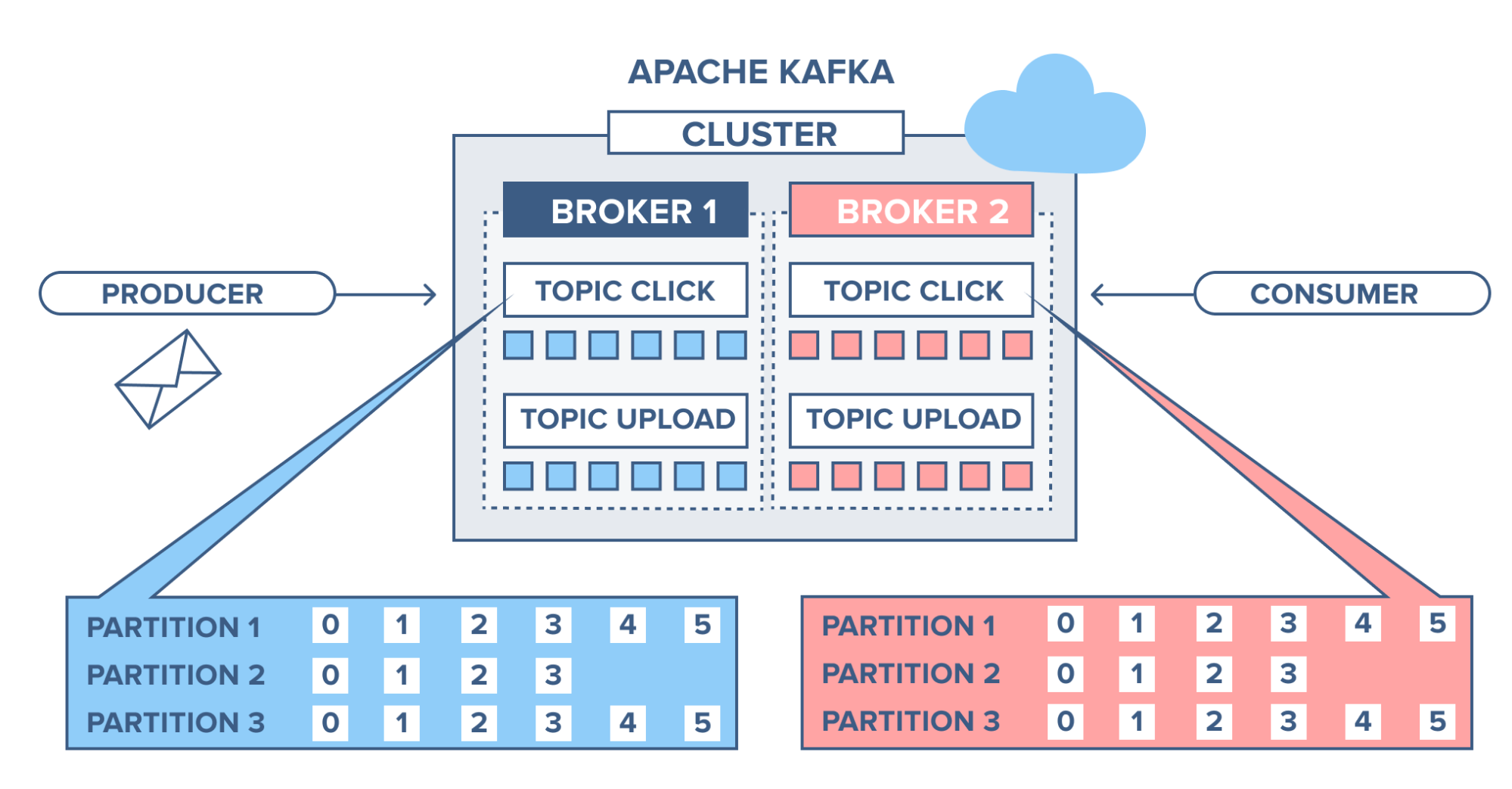
Brokers
A Kafka server is also called a Kafka broker. A Kafka cluster consists multiple brokers.
- Each broker has an integer identification number
- Each broker contains some topic partitions.
- Each broker can contain multiple partitions of same topic
- A producer or consumer can connect to any broker and in turn gets connected to the entire cluster.
Topic Replication Factor
- It’s always a wise decision to factor in topic replication while designing a Kafka system. This way, if a broker goes down, its topics’ replicas from another broker can solve the crisis. Let’s take a look into the below example. Here, we have 3 brokers and 3 topics. Broker1 has Topic 1 and Partition 0, it’s replica is in Broker2, so on and so forth. It has got a replication factor of 2; it means it will have one additional copy other than the primary one.
Couple of notes
- Replication happens in the partition level
- At a time, only one broker can be a leader for a given partition; other brokers will have in-sync replica; also known as ISR.
- You can’t have number of replication factor more than the number of available brokers.
- In normal circumstance, this leader partition will receive data from producer and consumers will read from the leader partition.
Broker
A Kafka cluster consists of one or more servers (Kafka brokers) running Kafka. Producers are processes that push records into Kafka topics within the broker. A consumer pulls records off a Kafka topic.
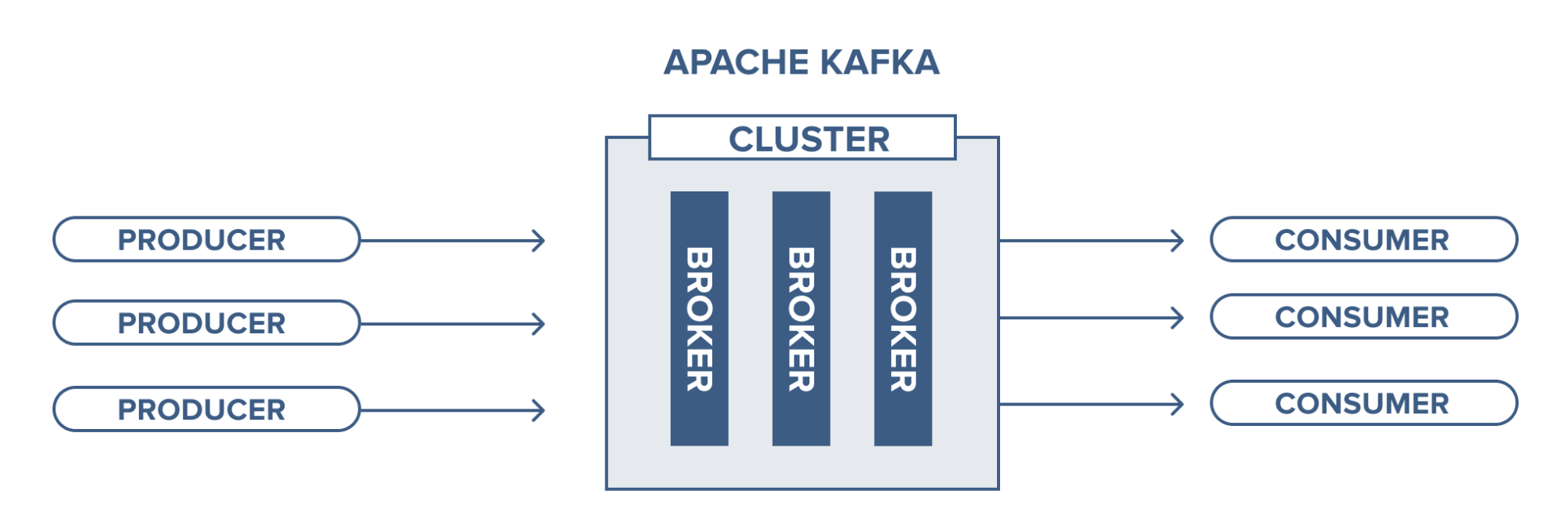
Source: https://www.cloudkarafka.com/
Running a single Kafka broker is possible but it doesn’t give all the benefits that Kafka in a cluster can give, for example, data replication.
Management of the brokers in the cluster is performed by Zookeeper. There may be multiple Zookeepers in a cluster, in fact the recommendation is three to five, keeping an odd number so that there is always a majority and the number as low as possible to conserve overhead resources.
Producers
Producers are the ones to write data to a topic
- Producers need to specify the topic name and one broker to connect to; Kafka will automatically take care of sending the data to the right partition of the right broker. Kafka will take care of the required load balancing among multiple partitions across multiple brokers.
- Producers have the provision to receive back the acknowledgement of the data it writes. There are following kinds of acknowledgements possible –
- acks =0 [In this case, producer does not wait for any acknowledgment. Producer writes the message to topic and moves on. In this way, producer won’t wait for acknowledgment. This is the fastest way of publishing the message to topic.]
- acks = 1 [In this case, producer will wait for only leader acknowledgment. It guarantees that atleast one broker has got the message; however there is no guarantee that the data has made it to the replicas.]
- acks=all [In this case, the leader and all the replicas will need to acknowledge back; this has worst possible performance impact among total 3 types.]
Consumers and consumer groups
Consumers can read messages starting from a specific offset and are allowed to read from any offset point they choose. This allows consumers to join the cluster at any point in time.
Low-level consumers
There are two types of consumers in Kafka. First, the low-level consumer, where topics and partitions are specified as is the offset from which to read, either fixed position, at the beginning or at the end. This can, of course, be cumbersome to keep track of which offsets are consumed so the same records aren’t read more than once. So Kafka added another easier way of consuming with:
High-level consumer
The high-level consumer (more known as consumer groups) consists of one or more consumers. Here a consumer group is created by adding the property “group.id” to a consumer. Giving the same group id to another consumer means it will join the same group.
The broker will distribute according to which consumer should read from which partitions and it also keeps track of which offset the group is at for each partition. It tracks this by having all consumers committing which offset they have handled.
Every time a consumer is added or removed from a group the consumption is rebalanced between the group. All consumers are stopped on every rebalance, so clients that time out or are restarted often will decrease the throughput. Make the consumers stateless since the consumer might get different partitions assigned on a rebalance.
Consumers pull messages from topic partitions. Different consumers can be responsible for different partitions. Kafka can support a large number of consumers and retain large amounts of data with very little overhead. By using consumer groups, consumers can be parallelized so that multiple consumers can read from multiple partitions on a topic, allowing a very high message processing throughput. The number of partitions impacts the maximum parallelism of consumers as there cannot be more consumers than partitions.
Records are never pushed out to consumers, the consumer will ask for messages when the consumer is ready to handle the message.
The consumers will never overload themselves with lots of data or lose any data since all records are being queued up in Kafka. If the consumer is behind during message processing, it has the option to eventually catch up and get back to handle data in real-time.
Record flow in Apache Kafka
Now we have been looking at the producer and the consumer, and we will check at how the broker receives and stores records coming in the broker.
We have an example, where we have a broker with three topics, where each topic has 8 partitions.
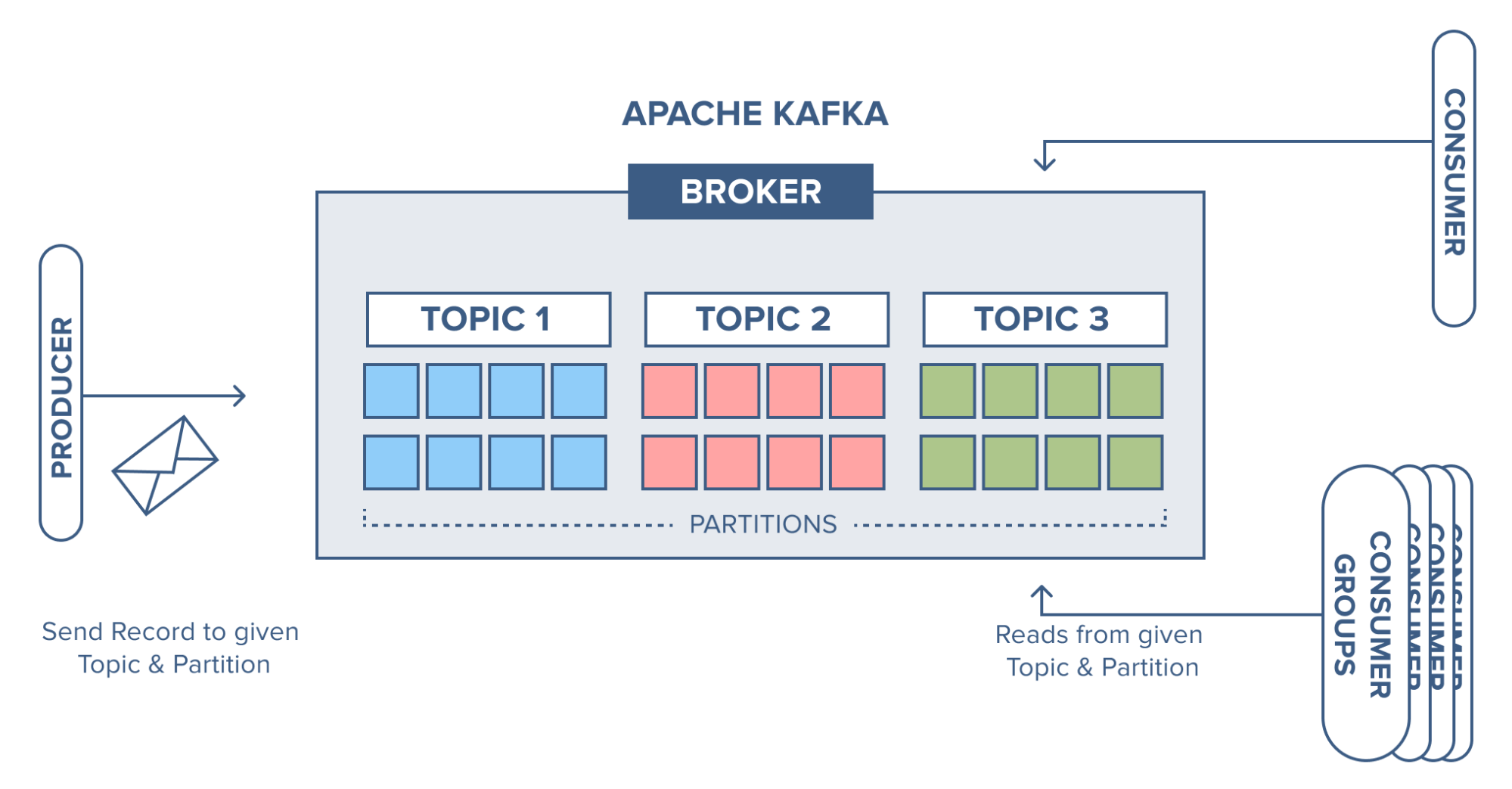
Source: https://www.cloudkarafka.com/
The producer sends a record to partition 1 in topic 1 and since the partition is empty the record ends up at offset 0.
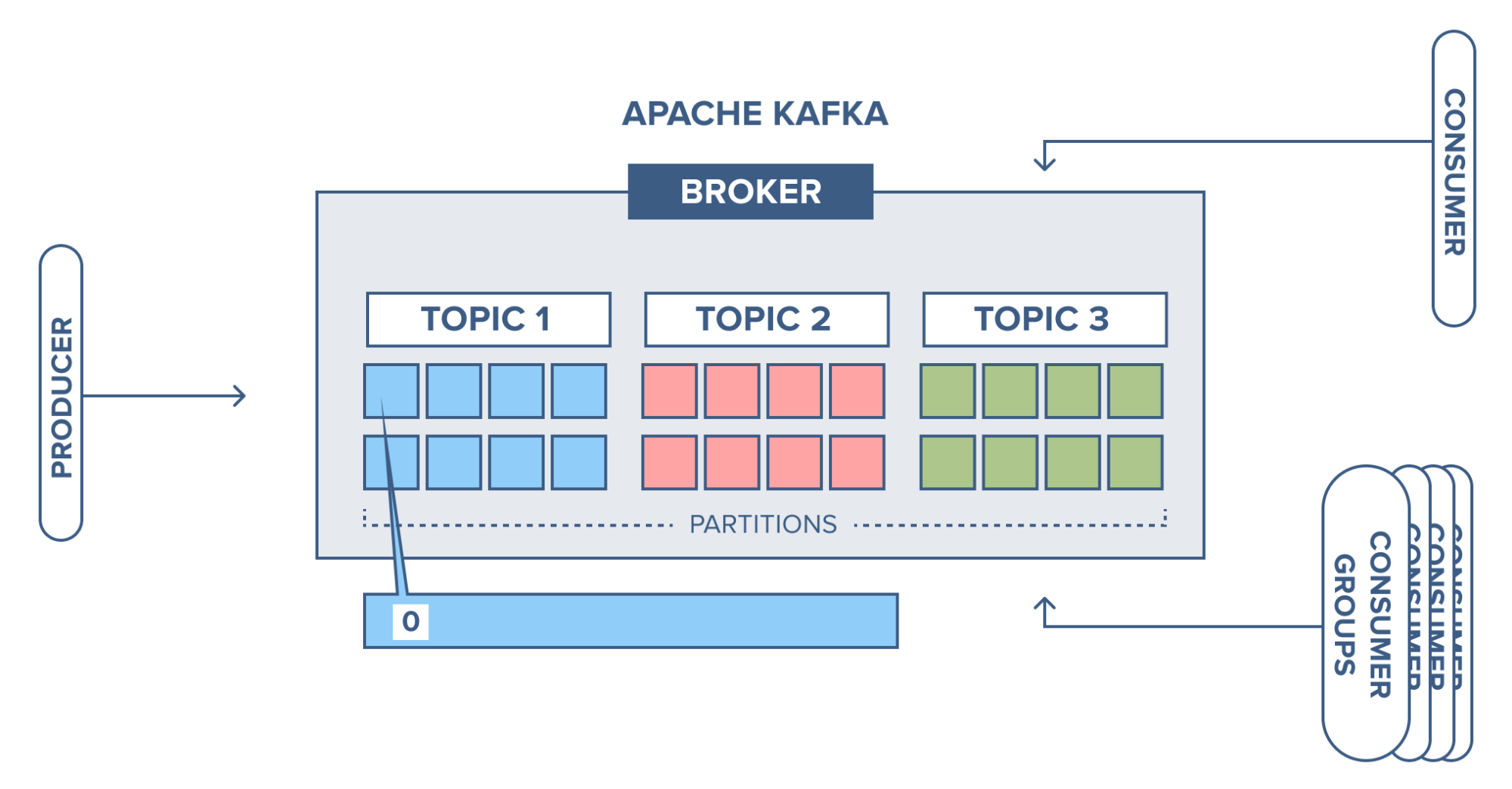
Source: https://www.cloudkarafka.com/
Next record is added to partition 1 will and up at offset 1, and the next record at offset 2 and so on.
Source: https://www.cloudkarafka.com/
This is what is referred to as a commit log, each record is appended to the log and there is no way to change the existing records in the log. This is also the same offset that the consumer uses to specify where to start reading.
Quick Start
Photo by Jon Tyson on Unsplash
STEP 1: GET KAFKA
Download the latest Kafka release and extract it:
$ tar -xzf kafka_2.13-2.6.0.tgz
$ cd kafka_2.13-2.6.0</span>
STEP 2: START THE KAFKA ENVIRONMENT
NOTE: Your local environment must have Java 8+ installed.
Run the following commands in order to start all services in the correct order:
# Start the ZooKeeper service
# Note: Soon, ZooKeeper will no longer be required by Apache Kafka.
$ bin/zookeeper-server-start.sh config/zookeeper.properties</span>
Open another terminal session and run:
# Start the Kafka broker service
$ bin/kafka-server-start.sh config/server.properties</span>
Once all services have successfully launched, you will have a basic Kafka environment running and ready to use.
STEP 3: CREATE A TOPIC TO STORE YOUR EVENTS
Kafka is a distributed event streaming platform that lets you read, write, store, and process events (also called records or messages in the documentation) across many machines.
Example events are payment transactions, geolocation updates from mobile phones, shipping orders, sensor measurements from IoT devices or medical equipment, and much more. These events are organized and stored in topics. Very simplified, a topic is similar to a folder in a filesystem, and the events are the files in that folder.
So before you can write your first events, you must create a topic. Open another terminal session and run:
$ bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092</span>
All of Kafka’s command line tools have additional options: run the kafka-topics.sh command without any arguments to display usage information. For example, it can also show you details such as the partition count of the new topic:
$ bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092
Topic:quickstart-events PartitionCount:1 ReplicationFactor:1 Configs:
Topic: quickstart-events Partition: 0 Leader: 0 Replicas: 0 Isr: 0</span>
STEP 4: WRITE SOME EVENTS INTO THE TOPIC
A Kafka client communicates with the Kafka brokers via the network for writing (or reading) events. Once received, the brokers will store the events in a durable and fault-tolerant manner for as long as you need — even forever.
Run the console producer client to write a few events into your topic. By default, each line you enter will result in a separate event being written to the topic.
$ bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092
This is my first event
This is my second event</span>
You can stop the producer client with Ctrl-C at any time.
STEP 5: READ THE EVENTS
Open another terminal session and run the console consumer client to read the events you just created:
$ bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
This is my first event
This is my second event</span>
You can stop the consumer client with Ctrl-C at any time.
Feel free to experiment: for example, switch back to your producer terminal (previous step) to write additional events, and see how the events immediately show up in your consumer terminal.
Because events are durably stored in Kafka, they can be read as many times and by as many consumers as you want. You can easily verify this by opening yet another terminal session and re-running the previous command again.
STEP 6: IMPORT/EXPORT YOUR DATA AS STREAMS OF EVENTS WITH KAFKA CONNECT
You probably have lots of data in existing systems like relational databases or traditional messaging systems, along with many applications that already use these systems. Kafka Connect allows you to continuously ingest data from external systems into Kafka, and vice versa. It is thus very easy to integrate existing systems with Kafka. To make this process even easier, there are hundreds of such connectors readily available.
Take a look at the Kafka Connect section learn more about how to continuously import/export your data into and out of Kafka.
STEP 7: PROCESS YOUR EVENTS WITH KAFKA STREAMS
Once your data is stored in Kafka as events, you can process the data with the Kafka Streams client library for Java/Scala. It allows you to implement mission-critical real-time applications and microservices, where the input and/or output data is stored in Kafka topics. Kafka Streams combines the simplicity of writing and deploying standard Java and Scala applications on the client side with the benefits of Kafka’s server-side cluster technology to make these applications highly scalable, elastic, fault-tolerant, and distributed. The library supports exactly-once processing, stateful operations and aggregations, windowing, joins, processing based on event-time, and much more.
To give you a first taste, here’s how one would implement the popular WordCount algorithm:
KTable<String, Long> wordCounts = textLines
.flatMapValues(line -> Arrays.asList(line.toLowerCase().split(" ")))
.groupBy((keyIgnored, word) -> word)
.count();</span><span id="0213" class="de ik il bo ms b gg mz na nb nc nd mu r mv">wordCounts.toStream().to("output-topic"), Produced.with(Serdes.String(), Serdes.Long()));</span>
The Kafka Streams demo and the app development tutorial demonstrate how to code and run such a streaming application from start to finish.
STEP 8: TERMINATE THE KAFKA ENVIRONMENT
Now that you reached the end of the quickstart, feel free to tear down the Kafka environment — or continue playing around.
- Stop the producer and consumer clients with
Ctrl-C, if you haven't done so already. - Stop the Kafka broker with
Ctrl-C. - Lastly, stop the ZooKeeper server with
Ctrl-C.
If you also want to delete any data of your local Kafka environment including any events you have created along the way, run the command:
$ rm -rf /tmp/kafka-logs /tmp/zookeeper</span>
Photo by Brett Garwood on Unsplash
You have successfully finished the Apache Kafka quickstart.
Thanks so much for your interest in my post! If it was useful for you, please remember to “LIKE” 🙂 or retweet the thread on twitter.
It so other people can also benefit from it.
If you have any suggestions or questions, please leave a comment!

Source