Downloadable Data & AI Landscape

I am from Italy, I live in a little city near Milan and I work as an Executive in an International Consultancy Firm with multi-faceted skills and 20+ years of experience spanning across the magic world of Data Science.
Hello Data Lovers👋
In this article, I'm talking about Data & AI Landscape. Do you know Matt Turck? Don't you? 😱 Naaaaaaa....This is a great mistake!
Matt’s work is one of the most eagerly awaited in Data & Analytics. The 2020 edition has finally come out.
In this article, there is a summary of the main points that emerged.
Are you ready? Let's go! 🚀
Introduction
According to Matt Turck “In a year like no other in recent memory, the data ecosystem is showing not just remarkable resilience but exciting vibrancy. When COVID hit the world a few months ago, an extended period of gloom seemed all but inevitable.
Yet, as per Satya Nadella,
two years of digital transformation [occurred] in two months.
Cloud and data technologies (data infrastructure, machine learning / artificial intelligence, data-driven applications) are at the heart of digital transformation.
As a result, many companies in the data ecosystem have not just survived, but in fact thrived, in an otherwise overall challenging political and economic context.”

Key trends in data infrastructure
There’s plenty going on in data infrastructure in 2020. As companies start reaping the benefits of the data/AI initiatives they started over the last few years, they want to do more: can we process more data, faster and cheaper? Deploy more ML models in production? Do more in real-time? Etc.
This, in turn, raises the bar on data infrastructure (and the teams building/maintaining it), and offers plenty of room for innovation, particularly in a context where the landscape keeps shifting (multi-cloud, etc.)
In the 2019 edition, we had highlighted a few trends:
- A third wave? From Hadoop to cloud services to Kubernetes + Snowflake
- Data governance, cataloging, lineage: the increasing importance of data management
- The rise of an AI-specific infrastructure stack (“MLOps”, “AIOps”)
While those trends are still very much accelerating, here are a few more that are very much top of mind in 2020.
The modern data stack goes mainstream
The concept of “modern data stack” (a set of tools and technologies that enable analytics, particularly for transactional data) is many years in the making — it started appearing as far back as 2012, with the launch of Redshift, Amazon’s cloud data warehouse.
But over the last couple of years, and perhaps even more so in the last 12 months, the popularity of cloud warehouses has grown explosively, and so has a whole ecosystem of tools and companies around them, going from the leading edge to mainstream.
The general idea behind the modern stack is the same as with older technologies: building a data pipeline where you first extract data from a bunch of different sources, store it in a centralized data warehouse, and then analyze and visualize it.
But the big shift has been the enormous scalability and elasticity of cloud data warehouses (Amazon Redshift, Snowflake, Google BigQuery, Microsoft Synapse, in particular).
They have become the cornerstone of the modern, cloud-first data stack and pipeline.
While there are all sorts of data pipelines (more on this later), the industry has been normalizing around a stack that looks something like this, at least for transactional data:
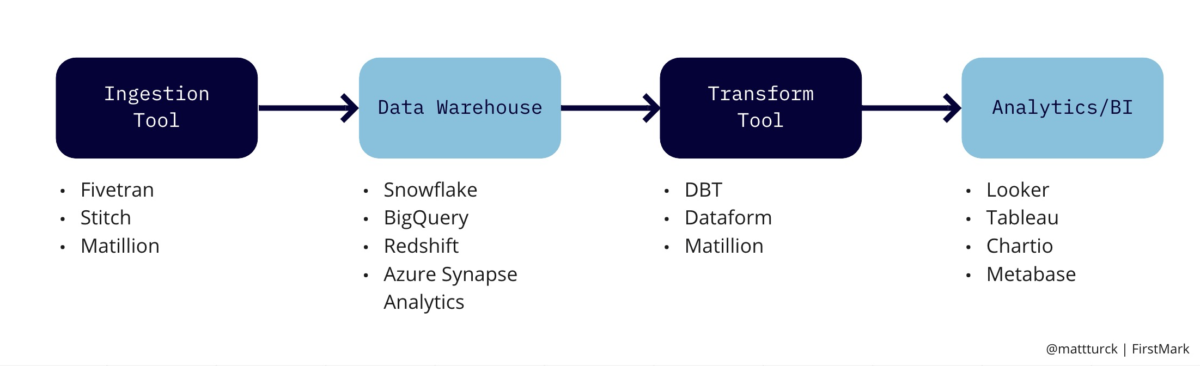
ETL vs ELT
Data warehouses used to be expensive and inelastic, so you had to heavily curate the data before loading into the warehouse: first, extract it data from sources, then transform it in the desired format, and finally, load into the warehouse (Extract, Transform, Load or ETL).
In the modern data pipeline, you can extract large amounts of data from multiple data sources, dump it all in the data warehouse without worrying about scale or format, and then transform the data directly inside the data warehouse — in other words, extract, load and transform (“ELT”).
A new generation of tools has emerged to enable this evolution from ETL to ELT.
Automation of Data Engineering?
ETL has traditionally been a highly technical area and largely gave rise to data engineering as a separate discipline. This is still very much the case today with modern tools like Spark that require real technical expertise.
However, in a cloud data warehouse centric paradigm, where the main goal is “just” to extract and load data, without having to transform it as much, there is an opportunity to automate a lot more of the engineering task.
Rise of the Data Analyst
An interesting consequence of the above is that data analysts are taking on a much more prominent role in data management and analytics.
Data analysts are non-engineers who are proficient in SQL, a language used for managing data held in databases. They may also know some Python, but they are typically not engineers. Sometimes they are a centralized team, sometimes they are embedded in various departments and business units.
Traditionally, data analysts would only handle the last mile of the data pipeline — analytics, business intelligence, visualization.
Now, because cloud data warehouses are big relational databases (forgive the simplification), data analysts are able to go much deeper into the territory that was traditionally handled by data engineers, and for example handle transformations, leveraging their SQL skills (DBT, Dataform, and others being SQL based frameworks).
This is good news as data engineers continue to be rare and expensive. There are many more (10x more?) data analysts and they are much easier to train.
Data lakes and data warehouses merging?
Another trend towards simplification of the data stack is the unification of data lakes and data warehouses. Some (like Databricks) call this trend the “data lakehouse”, others call it the “Unified Analytics Warehouse”.
Data Lakehouse is the new trend in Data & AI field 🚀
Historically, you’ve had data lakes on one side (big repositories for raw data, in a variety of formats, that are low-cost, very scalable but don’t support transactions, data quality, etc.) and then data warehouses on the other side (a lot more structured, with transactional capabilities and more data governance features).
Data lakes have had a lot of use cases for machine learning, whereas data warehouses have supported more transactional analytics and business intelligence.
The net result is that, in many companies, the data stack includes a data lake and sometimes several data warehouses, with many parallel data pipelines.
Companies in the space are now trying to merge both sides, with a “best of both worlds” goal, and a unified experience for all types of data analytics, including both BI and machine learning.
Complexity remains
A lot of the above points towards greater simplicity and approachability of the data stack in the enterprise.
However, this trend is counterbalanced by an even faster increase in complexity.
The overall volume of data flowing through the enterprise continues to grow at an explosive pace.
The number of sources of data keeps increasing as well, with ever more SaaS tools.
There is not one but many data pipelines operating in parallel in the enterprise.
The modern data stack mentioned above is largely focused on the world of transactional data and BI style analytics. Many machine learning pipelines are altogether different.
There’s also an increasing need for real-time streaming technologies, which the modern stack mentioned above is in the very early stages of addressing (it’s very much a batch processing paradigm for now).
For this reason, the more complex tools, including those for micro-batching (Spark) and streaming (Kafka and, increasingly, Pulsar) continue to have a bright future ahead of them.
Trends in analytics & enterprise ML/AI
DSML platforms are the cornerstone of the deployment of machine learning and AI in the enterprise.
The top companies in the space have experienced considerable market traction in the last couple of years and are reaching a large scale.
While they came at the opportunity from different starting points, the top platforms have been gradually expanding their offering to serve more constituencies and address more use cases in the enterprise.
The Year of NLP
It’s been a particularly great last 12 months (or 24 months) for NLP, a branch of artificial intelligence focused on understanding natural language.
The last year has seen continued advancements in NLP from a variety of players including large cloud providers (Google), nonprofits (Open AI, which raised $1B from Microsoft in July 2019) and startups. For a great overview, see this talk from Clement Delangue, CEO of Hugging Face: NLP — The Most Important Field of ML
Some noteworthy developments:
- Transformers, which have been around for some time, and pre-trained language models continue to gain popularity. These are the model of choice for NLP as they permit much higher rates of parallelization and thus larger training data sets.
- Google rolled out BERT, the NLP system underpinning Google Search, to 70 new languages.
- Google also released ELECTRA, which performs similarly on benchmarks to language models such as GPT and masked language models such as BERT, while being much more compute efficiently.
- We are also seeing the adoption of NLP products that make training models more accessible. For example, Monkey Learn allows non-technical folks to train models on proprietary corpora of text.
- And, of course, the GPT-3 release was greeted with much fanfare. This is a 175B parameter model out of Open AI, more than two orders of magnitude larger than GPT-2.
Thanks for reading! If it was useful to you, please Like/Share so that, it reaches others as well.
📧 To get e-mail notification on my latest posts, please subscribe to my blog by hitting the Subscribe button at the top of the page. 📧
Stay Tuned.

Credit:
You can find Matt’s original article here.




