Google Analysis of Online Dataset

I am from Italy, I live in a little city near Milan and I work as an Executive in an International Consultancy Firm with multi-faceted skills and 20+ years of experience spanning across the magic world of Data Science.
According to Google AI Blog there are tens of millions of datasets on the web, with content ranging from sensor data and government records, to results of scientific experiments and business reports. Indeed, there are datasets for almost anything one can imagine, be it diets of emperor penguins or where remote workers live.
More than two years ago, we undertook an effort to design a search engine that would provide a single entry point to these millions of datasets and thousands of repositories. The result is Dataset Search, which we launched in beta in 2018 and fully launched in January 2020. In addition to facilitating access to data, Dataset Search reconciles and indexes datasets using the metadata descriptions that come directly from the dataset web pages using schema.org structure.
As of today, the complete Dataset Search corpus contains more than 31 million datasets from more than 4,600 internet domains. About half of these datasets come from .com domains, but .org and governmental domains are also well represented.
The graph below shows the growth of the corpus over the last two years, and while we still don’t know what fraction of datasets on the web are currently in Dataset Search, the number continues to grow steadily.
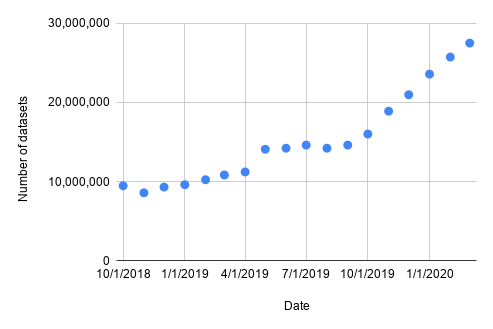
To better understand the breadth and utility of the datasets made available through Dataset Search, we published “Google Dataset Search by the Numbers”, accepted at the 2020 International Semantic Web Conference.
Here we provide an overview of the available datasets, present metrics and insights originating from their analysis, and suggest best practices for publishing future scientific datasets. In order to enable other researchers to build analysis and tools using the metadata, we are also making a subset of the data publicly available.
A Range of Dataset Topics
In order to determine the distribution of topics covered by the datasets, we infer the research category based on dataset titles and descriptions, as well as other text on the dataset Web pages. The two most common topics are geosciences and social sciences, which account for roughly 45% of the datasets. Biology is a close third at ~15%, followed by a roughly even distribution for other topics, including computer science, agriculture, and chemistry, among others.
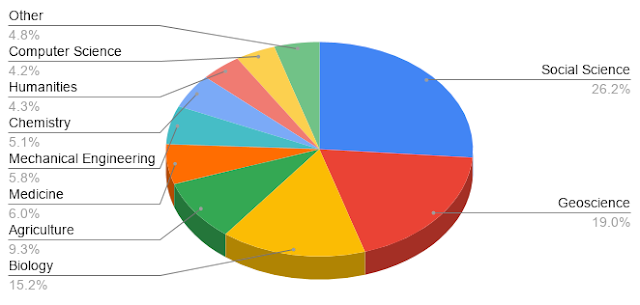
In our initial efforts to launch Dataset Search, we reached out to specific communities, which was key to bootstrapping widespread use of the corpus. Initially, we focused on geosciences and social sciences, but since then, we have allowed the corpus to grow organically.
We were surprised to see that the fields associated with the communities we reached out to early on are still dominating the corpus. While their early involvement certainly contributes to their prevalence, there may be other factors involved, such as differences in culture across communities. For instance, geosciences have been particularly successful in making their data findable, accessible, interoperable, and reusable (FAIR), a core component to reducing barriers for access.
Start the journey
My Journey with the #2articles1week challenge from HashNode start now.





